工作负载
ℹ️ 前提
已开启Kubectl连接工作空间,详情请参考:连接工作空间。
在 Kubernetes 中,工作负载(Workload)是对一组容器组(Pod)的抽象,代表业务的运行载体。常见类型包括:
无状态工作负载(Deployment)
有状态工作负载(StatefulSet)
守护进程(DaemonSet)
批处理任务(Job)
开发机实例(ContainerServer)
每种工作负载类型都针对不同场景设计,统一管理容器的部署、伸缩和调度。
工作负载生命周期说明
| 状态 | 说明 |
|---|---|
| 排队中 | 任务已创建,等待调度阶段,实例未创建或者所有实例状态为排队中。 |
| 启动中 | Pod调度完成,实例的状态均为启动中或者包含部分运行中的状态。 |
| 运行中 | 所有的Pod为运行中的状态。 |
| 未知 | Pod Terminating、Failed、ImagePullBackOff、unknown、NodeLost、CrashLoopBackOff等状态。 |
| 成功 | 负载成功结束,所有实例状态为 成功。 |
NCCL-Test示例
NCCL-Test 是 NVIDIA 提供的一套用于测试多机多卡 GPU 通信带宽、延迟的基准测试工具,以下是如何发起一个类型为MPIJob的工作负载的示例。
- 在集群中预先安装Kubeflow Training Operator(v1.8.0)
yaml
kubectl apply --force-conflicts --server-side -k "https://ghfast.top/github.com/kubeflow/training-operator.git/manifests/overlays/standalone?ref=v1.8.0"- H800两机16卡的NCCL-Test,示例nccl-test.yaml如下:
yaml
apiVersion: kubeflow.org/v1
kind: MPIJob
metadata:name: nccl-test
spec:slotsPerWorker: 8 # 每个Worker使用8个slot(对应8张GPU)cleanPodPolicy: Running
mpiReplicaSpecs:Launcher:replicas: 1 # 启动一个 Launcher Podtemplate:spec:affinity:nodeAffinity: # Pod调度亲和性requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: cloud.ebtech.com/cpu # CPU节点的标签operator: In
values:- amd-epyc-milan
containers:#- image: registry-cn-huabei1-internal.ebcloud.com/job-template/nccl-tests:v2.13.8-nccl2.23.4-ibperf24.07.0-cuda12.0.1-cudnn8-devel-ubuntu20.04-1- image: registry-cn-huabei1-internal.ebcloud.com/job-template/nccl-tests:12.2.2-cudnn8-devel-ubuntu20.04-nccl2.21.5-1-2ff05b2
name: mpi-launcher
command: ["/bin/bash", "-c"]args: [
"sleep 20 && \
mpirun \
--mca btl_tcp_if_include bond0 \
-np 16 \
--allow-run-as-root \
-bind-to none \
-x LD_LIBRARY_PATH \
-x NCCL_IB_DISABLE=0 \
-x NCCL_IB_HCA=mlx5_100,mlx5_101,mlx5_102,mlx5_103,mlx5_104,mlx5_105,mlx5_106,mlx5_107 \
-x NCCL_SOCKET_IFNAME=bond0 \
-x SHARP_COLL_ENABLE_PCI_RELAXED_ORDERING=1 \
-x NCCL_COLLNET_ENABLE=0 \
-x NCCL_ALGO=NVLSTREE \
-x NCCL_DEBUG=INFO \
-x NCCL_DEBUG_SUBSYS=all \
-x NCCL_DEBUG_FILE=/data/nccl.%h.%p.log \
-x NCCL_TOPO_DUMP_FILE=/data/a_topo.xml \
-x NCCL_GRAPH_DUMP_FILE=/data/a_graph.xml \
/opt/nccl_tests/build/all_reduce_perf -b 512M -e 8G -f 2 -g 1 #-n 200 #-w 2 -n 20
",]resources:limits:cpu: "1"memory: "2Gi"Worker:replicas: 2 # 启动 2 个 Worker Podtemplate:spec:hostNetwork: truehostPID: trueaffinity:nodeAffinity: # Pod调度亲和性requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: cloud.ebtech.com/gpu # 节点的标签operator: In
values:- H800_NVLINK_80GB
#- key: ring#operator: In#values:#- ffvolumes:- emptyDir:medium: Memory
name: dshm
- name: file
persistentVolumeClaim:claimName: train
containers:#- image: registry-cn-huabei1-internal.ebcloud.com/job-template/nccl-tests:v2.13.8-nccl2.23.4-ibperf24.07.0-cuda12.0.1-cudnn8-devel-ubuntu20.04-1- image: registry-cn-huabei1-internal.ebcloud.com/job-template/nccl-tests:12.2.2-cudnn8-devel-ubuntu20.04-nccl2.21.5-1-2ff05b2
name: mpi-worker
command: ["/bin/bash", "-c"]volumeMounts:- mountPath: /dev/shm
name: dshm
- mountPath: /data
name: file
securityContext:capabilities:add:- IPC_LOCK
# - SYS_RESOURCEargs:- |
echo "Starting SSH Server..."
/usr/sbin/sshd -De &
sleep infinityresources:limits:nvidia.com/gpu: 8 # 每个Worker请求8张GPUrdma/hca_shared_devices_ib: 8 # 启用RDMA- 执行yaml
yaml
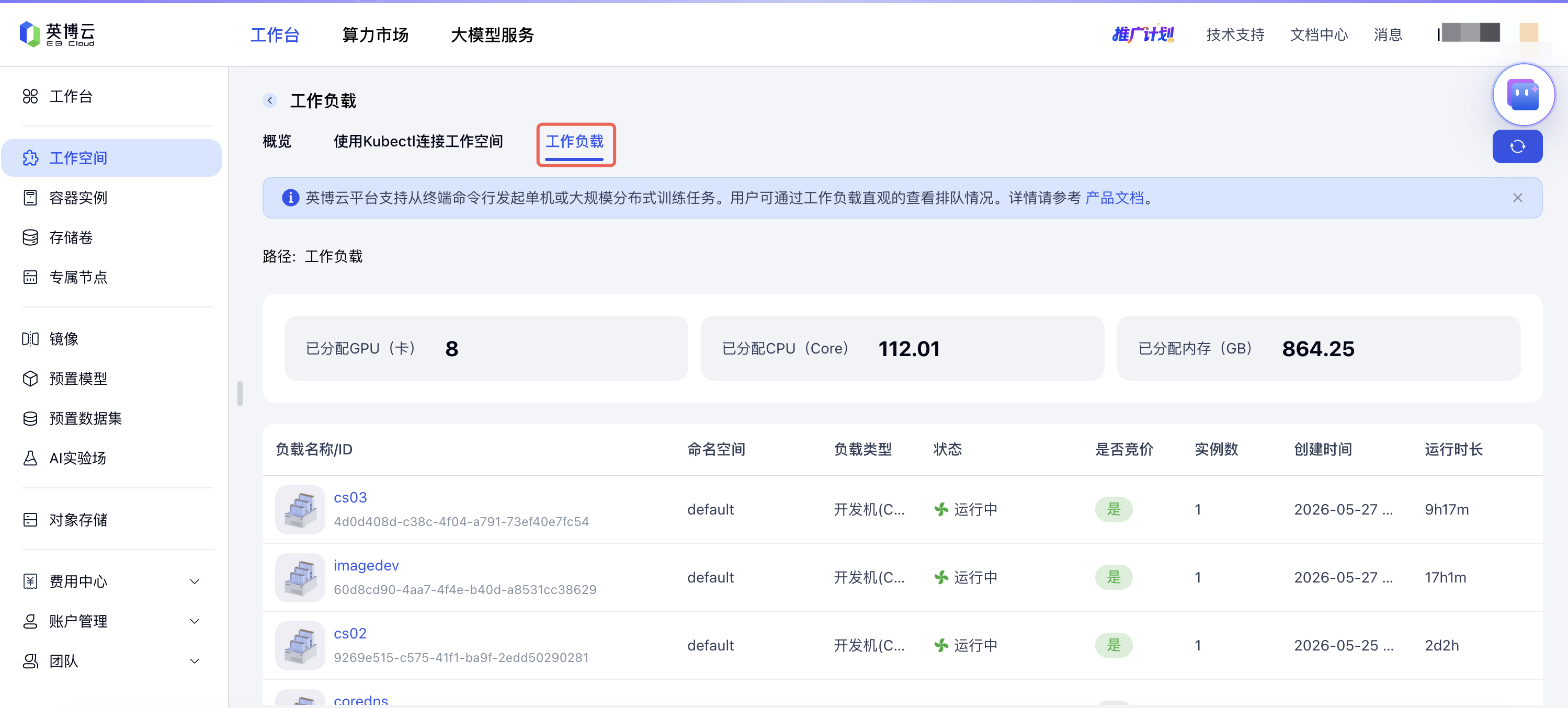
kubectl apply -f nccl-test.yaml工作负载查看
登录英博云控制台。
在页面左侧导航栏,选择 工作空间,进入工作空间列表页面。
单击单个工作空间名称进入详情页,点击上方「工作负载」,进入工作负载列表页