'%3e%3cpath%20d='M14.584%204.27734L21.9274%208.55391V23.9564L14.584%2019.6798V4.27734Z'%20fill='%2368E053'/%3e%3cpath%20d='M7.34375%2024.2458L14.6871%2028.5224L21.9284%2023.9563L14.5849%2019.6797L7.34375%2024.2458Z'%20fill='%2359C239'/%3e%3cpath%20d='M0%204.58398L7.34342%208.86055V24.263L0%2019.9864V4.58398Z'%20fill='%232E4EF5'/%3e%3cpath%20d='M0%204.58325L7.34342%208.85981L14.5846%204.27657L7.2412%200L0%204.58325Z'%20fill='%23306FF5'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M32.134%202.5H34.073V3.95418H38.7817V2.5H40.6513V3.95418H44.1829V5.26987H40.6513V7.00103H38.7817V5.26987H34.073V7.00103H32.134V5.26987H28.5332V3.95418H32.134V2.5ZM37.3981%206.86328H35.5285V7.97123H30.6119V11.7798H28.6038V13.3724H35.5285V13.8572L28.5%2019.3969L31.0967%2019.5008L36.4287%2015.3114L42.0031%2019.3969H44.4266L37.3981%2013.8572V13.3724H44.4613V11.7798H42.4532V7.97123H37.3981V6.86328ZM32.5509%209.28693V11.7798H35.5285V9.28693H32.5509ZM37.3981%2011.7798V9.28693H40.5834V11.7798H37.3981ZM55.7496%202.5H57.6885V4.30041H61.9125V5.26987H57.6885V5.89309H61.6355V11.5092C61.6355%2011.6241%2061.5422%2011.7172%2061.4272%2011.7169L58.5195%2011.7097V10.7403H59.7659V10.3249H57.6885V12.3331H55.7496V10.3249H54.1569V11.6405H52.218V5.89309H55.7496V5.26987H51.6641V4.30041H55.7496V2.5ZM54.1569%206.86253V7.555H55.7496V6.86253H54.1569ZM57.6885%206.86253V7.555H59.7659V6.86253H57.6885ZM54.1569%208.52446V9.35538H55.7496V8.52446H54.1569ZM57.6885%208.52446V9.35538H59.7659V8.52446H57.6885ZM50.4867%202.70703H48.617V6.10012H46.9551V7.5543H48.617V19.1878H50.4867V7.5543H51.8716V6.10012H50.4867V2.70703ZM60.874%2012.2637H59.0043V12.6099H51.8027V14.1333H59.0043V18.0111H56.3038L56.65%2019.1884H60.874V14.1333H62.2589V12.6099H60.874V12.2637ZM56.9265%2014.8945H53.6719L54.0181%2016.3487H57.3419L56.9265%2014.8945ZM61.1485%202.70703H58.8633L59.2095%203.81498H61.4947L61.1485%202.70703ZM66.6719%203.2168H79.0052V4.62452H66.6719V3.2168ZM65.6543%208.70703H80.0257V10.1148H70.8852L68.6858%2016.3148V17.2186L76.5439%2017.1485L75.6054%2014.6615H77.6084L79.2052%2018.8789H77.9236H77.2022H66.8789V15.8805L68.9924%2010.1148H65.6543V8.70703Z'%20fill='%23020617'/%3e%3cpath%20fill-rule='evenodd'%20clip-rule='evenodd'%20d='M35.1498%2021.7207H29.8315L29.0001%2022.6114L29%2025.7296L29.8313%2026.6204L35.1498%2026.6205V25.8118H30.1331L29.8088%2025.4556V22.8855L30.133%2022.5294H35.1498V21.7207ZM44.2616%2021.721L38.4319%2021.7208V26.6206L44.2616%2026.6207L45.0928%2025.7299V22.6117L44.2616%2021.721ZM39.2407%2025.8119V22.5296H43.9598L44.2841%2022.8858V23.7095H40.0794V24.5182H44.2841V25.4557L43.9598%2025.8119H39.2407ZM35.1498%2023.7093H30.4205V24.5181H35.1498V23.7093ZM58.7072%2021.7246H53.294L53.1593%2021.8818C53.0539%2022.0048%2052.9711%2022.1017%2052.8887%2022.1981L52.8873%2022.1998L52.8859%2022.2014C52.8035%2022.2979%2052.7211%2022.3943%2052.6161%2022.5169L52.5078%2022.6433V25.693L52.6161%2025.8194C52.7216%2025.9425%2052.8046%2026.0396%2052.8873%2026.1365L52.8877%2026.1369C52.9704%2026.2338%2053.0534%2026.3309%2053.1593%2026.4545L53.294%2026.6117H58.7989V25.7117H53.7079L53.5713%2025.5517L53.4075%2025.3602V22.9761L53.5713%2022.7845L53.7079%2022.6246H58.7072V21.7246ZM67.2254%2022.8677H63.6288L63.0125%2023.4842V26.0093L63.3319%2026.3288L63.4017%2026.3985L63.6288%2026.6257H67.2254L67.659%2026.192L67.8417%2026.0093V23.4842L67.2254%2022.8677ZM63.9123%2023.857L64.0015%2023.7677H66.8528L66.942%2023.857V25.6365L66.8528%2025.7257H64.0015L63.9123%2025.6365V23.857ZM68.8604%2023.0002H69.7601V25.5378C69.8143%2025.6014%2069.8624%2025.6573%2069.9159%2025.7187H72.7353C72.7889%2025.6559%2072.8387%2025.5983%2072.8957%2025.5331V23.0002H73.7954V25.8735L73.6825%2026.0011C73.523%2026.1815%2073.4406%2026.2777%2073.2868%2026.4594L73.1521%2026.6187H69.5097L69.3754%2026.4669C69.2104%2026.2803%2069.1235%2026.1789%2068.9668%2025.9937L68.8604%2025.8678V23.0002ZM60.6988%2021.8289V26.5005H61.5985V21.8289H60.6988ZM78.6036%2024.5813V23.7679H75.6552L75.566%2023.8571V25.6366L75.6552%2025.7258H78.5041L78.6039%2025.6275V24.5813H78.6036ZM79.5036%2023.6566V21.7939H78.6036V22.8679H75.2826L74.6663%2023.4843V26.0094L75.2826%2026.6258H78.8058V26.4814L78.9109%2026.5883L79.5039%2026.0044V23.6566H79.5036Z'%20fill='%23020617'/%3e%3c/g%3e%3cdefs%3e%3cclipPath%20id='clip0_6697_31479'%3e%3crect%20width='82'%20height='28.5217'%20fill='white'/%3e%3c/clipPath%3e%3c/defs%3e%3c/svg%3e)
通过 Open WebUI 接入QwQ-32B模型服务
Open WebUI 是一个可扩展、功能丰富、用户友好的自托管人工智能平台,支持各种 LLM 运行程序。本文为您详细介绍用户如何通过 Open WebUI 高效调用 QwQ-32B API 服务并开启联网搜索功能。
QwQ-32B 的模型服务部署
QwQ-32B 在 32B 的规模上,提供了出色的推理能力。我们提供了几种不同的部署方案:
- 1xA800:单请求吞吐 23 token/s
- 2xA800:单请求吞吐 40 token/s,支持较高并发
- 4xA800:单请求吞吐 62 token/s,支持更高并发
- 本文中使用1卡A800作为演示,创建并编辑 inference.tpl.yaml 文件:vi inference.tpl.yaml,文件中包含模型服务Deployment和公网IP的Service,yaml示例如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: qwq-32b-1
namespace: default
labels:
app: qwq-32b-1
spec:
replicas: 1
selector:
matchLabels:
app: qwq-32b-1
template:
metadata:
labels:
app: qwq-32b-1
spec:
affinity: # Pod调度亲和性,选择合适的 GPU 卡型号
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: cloud.ebtech.com/gpu
operator: In
values:
- A800_NVLINK_80GB
volumes:
# 挂载共享模型数据大盘(如需要)
- name: models
hostPath:
path: /public
- name: shm
emptyDir:
medium: Memory
sizeLimit: "50Gi"
containers:
- name: qwq-32b
image: registry-cn-huabei1-internal.ebcloud.com/docker.io/lmsysorg/sglang:v0.4.5-cu125
command:
- bash
- "-c"
- |
python3 -m sglang.launch_server \
--model-path /public/huggingface-models/Qwen/QwQ-32B \
--tp "1" \
--host 0.0.0.0 --port 8000 \
--trust-remote-code \
--context-length 65536 \
--served-model-name qwq-32b \
--tool-call-parser qwen25
env:
- name: HF_DATASETS_OFFLINE
value: "1"
- name: TRANSFORMERS_OFFLINE
value: "1"
- name: HF_HUB_OFFLINE
value: "1"
ports:
- containerPort: 8000
resources:
limits:
cpu: "10"
memory: 100G
nvidia.com/gpu: "1"
requests:
cpu: "10"
memory: 100G
nvidia.com/gpu: "1"
volumeMounts:
- name: shm
mountPath: /dev/shm
# 挂载共享模型数据大盘(如需要)
- name: models
mountPath: /public
---
apiVersion: v1
kind: Service
metadata:
name: qwq-32b-1
namespace: default
spec:
ports:
- name: http-qwq-32b-1
port: 80
protocol: TCP
targetPort: 8000
# The label selector should match the deployment labels & it is useful for prefix caching feature
selector:
app: qwq-32b-1
sessionAffinity: None
# 指定 LoadBalancer 类型,用于将服务暴露到外部,自动分配公网 IP
type: LoadBalancer
# 部署 QwQ-32B 的模型服务,同时会部署一个 service,用于后续 API 调用
kubectl apply -f inference.tpl.yaml
# 查看部署的 pod
kubectl get pod
# 查看公网 IP,下面命令对应的输出中,Open WebUI 服务对应 External IP 即为分配到的公网 IP。
kubectl get service
# 查看 pod 日志
kubectl logs -f <YOUR-POD-NAME>
出现如下日志,即表示模型服务启动完成:
Loading safetensors checkpoint shards: 93% Completed | 13/14 [00:35<00:02, 2.79s/it]
Loading safetensors checkpoint shards: 100% Completed | 14/14 [00:38<00:00, 2.81s/it]
Loading safetensors checkpoint shards: 100% Completed | 14/14 [00:38<00:00, 2.75s/it]
[2025-04-09 13:43:07 TP0] Load weight end. type=Qwen2ForCausalLM, dtype=torch.bfloat16, avail mem=17.75 GB, mem usage=61.17 GB.
[2025-04-09 13:43:07 TP0] KV Cache is allocated. #tokens: 33901, K size: 4.14 GB, V size: 4.14 GB
[2025-04-09 13:43:07 TP0] Memory pool end. avail mem=8.72 GB
[2025-04-09 13:43:07 TP0] Capture cuda graph begin. This can take up to several minutes. avail mem=8.09 GB
Capturing batches (avail_mem=6.62 GB): 100%|██████████| 23/23 [00:07<00:00, 3.09it/s]
[2025-04-09 13:43:14 TP0] Capture cuda graph end. Time elapsed: 7.45 s. avail mem=6.60 GB. mem usage=1.49 GB.
[2025-04-09 13:43:15 TP0] max_total_num_tokens=33901, chunked_prefill_size=8192, max_prefill_tokens=16384, max_running_requests=2049, context_len=65536
[2025-04-09 13:43:15] INFO: Started server process [1]
[2025-04-09 13:43:15] INFO: Waiting for application startup.
[2025-04-09 13:43:15] INFO: Application startup complete.
[2025-04-09 13:43:15] INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
- 调用测试,验证服务是否可以正常调用
# 登录到容器内进行调试
kubectl exec -it <pod-name> -- bash
# 批式调用接口
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/public/huggingface-models/Qwen/QwQ-32B",
"prompt": "github是什么",
"max_tokens": 100,
"temperature": 0
}'
# 流式调用接口
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/public/huggingface-models/Qwen/QwQ-32B",
"prompt": "github是什么",
"max_tokens": 100,
"temperature": 0,
"stream": 1
}'
# 测试公网IP暴露的服务可用性
curl http://<YOUR-PUBLIC-IP>:80/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/public/huggingface-models/Qwen/QwQ-32B",
"prompt": "github是什么",
"max_tokens": 100,
"temperature": 0,
}'
- 至此QwQ-32B模型服务部署完成,若服务后续不再需要,需要删除资源和公网IP,请执行以下命令删除部署的所有资源:
kubectl delete -f inference.tpl.yaml
Open WebUI 的部署
我们使用开源方案 Open WebUI 来部署一个前端页面,承接交互式聊天的使用场景。
- 部署 Open WebUI的示例 owebui.tpl.yaml,文件中包含Deployment和公网IP的Service以及一个1GiB的共享存储卷PVC,yaml示例如下:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: owebui-data # 存储卷的名称
spec:
accessModes:
- ReadWriteMany # 存储卷的读写模式
resources:
requests:
storage: 1Gi # 存储卷的容量大小
storageClassName: shared-nvme-cn-huabei1 # 创建存储卷使用的StorageClass的名字
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: owebui-1
namespace: default
labels:
app: owebui-1
spec:
replicas: 1
selector:
matchLabels:
app: owebui-1
template:
metadata:
labels:
app: owebui-1
spec:
volumes:
# 挂载共享模型数据大盘(如需要)
- name: models
hostPath:
path: /public
# 挂载分布式存储盘(如需要)
- name: data
persistentVolumeClaim:
claimName: owebui-data
- name: shm
emptyDir:
medium: Memory
sizeLimit: "2Gi"
containers:
- name: owebui
image: registry-cn-huabei1-internal.ebcloud.com/ghcr.io/open-webui/open-webui:ollama
command:
- bash
- "-c"
- |
# pip install huggingface_hub[hf_xet] -i https://pypi.tuna.tsinghua.edu.cn/simple
# prepare open-webui data dir
mkdir -p /data/owebui-data/data
rm -rf /app/backend/data
ln -s /data/owebui-data/data /app/backend/
# prepare ollama models dir
mkdir -p /data/ollama-data
rm -rf /root/.ollama
ln -s /data/ollama-data /root/.ollama
# echo "pulling llama3.2:1b ..."
# ollama pull llama3.2:1b
# prepare open-webui secret key
if [ ! -f /app/backend/data/.webui_secret_key ]; then
echo $(head -c 12 /dev/random | base64) > /app/backend/data/.webui_secret_key
fi
ln -s /app/backend/data/.webui_secret_key /app/backend/.webui_secret_key
# comment out lines containing "application/json" in images.py
sed -i '/application\/json/s/^/#/' /app/backend/open_webui/routers/images.py
# start open-webui
bash /app/backend/start.sh
env:
- name: HF_ENDPOINT
value: "https://hf-mirror.com"
- name: ENABLE_EVALUATION_ARENA_MODELS
value: "false"
- name: RAG_EMBEDDING_MODEL
value: "/public/huggingface-models/sentence-transformers/all-MiniLM-L6-v2"
# - name: ENABLE_OPENAI_API # 不带模型服务(OpenAI_API_BASE_URL/OpenAI_API_BASE_URLS)启动时,取消掉这里的注释,以避免对 openai 官方 API 的依赖
# value: "false"
- name: OPENAI_API_KEYS # 多个 API Key 用分号分隔
value: "sk-foo-bar"
- name: OPENAI_API_BASE_URLS # 多个 API Base URL 用分号分隔
value: "http://<YOUR-PUBLIC-IP>/v1"
- name: ENABLE_WEB_SEARCH
value: "true"
- name: WEB_SEARCH_ENGINE
value: "searxng"
- name: SEARXNG_QUERY_URL
value: "http://searxng-1/search?q=<query>"
ports:
- containerPort: 8080
resources:
limits:
cpu: "2"
memory: 4G
requests:
cpu: "2"
memory: 4G
volumeMounts:
- name: shm
mountPath: /dev/shm
# 挂载共享模型数据大盘(如需要)
- name: models
mountPath: /public
# 挂载分布式存储盘(如需要)
- name: data
mountPath: /data
---
apiVersion: v1
kind: Service
metadata:
name: owebui-1
namespace: default
spec:
ports:
- name: http-owebui-1
port: 80
protocol: TCP
targetPort: 8080
# The label selector should match the deployment labels & it is useful for prefix caching feature
selector:
app: owebui-1
sessionAffinity: None
# 指定 LoadBalancer 类型,用于将服务暴露到外部,自动分配公网 IP
type: LoadBalancer
# type: ClusterIP
# 部署 Open WebUI,跟随它会同时申请一个公网 IP,方便我们在本地浏览器访问、使用它
kubectl apply -f owebui.tpl.yaml
# 查看公网 IP,下面命令对应的输出中,Open WebUI 服务对应 External IP 即为分配到的公网 IP。
kubectl get service
查看到公网 IP 后,直接在浏览器访问该 IP 即可打开我们部署的 Open WebUI 页面。 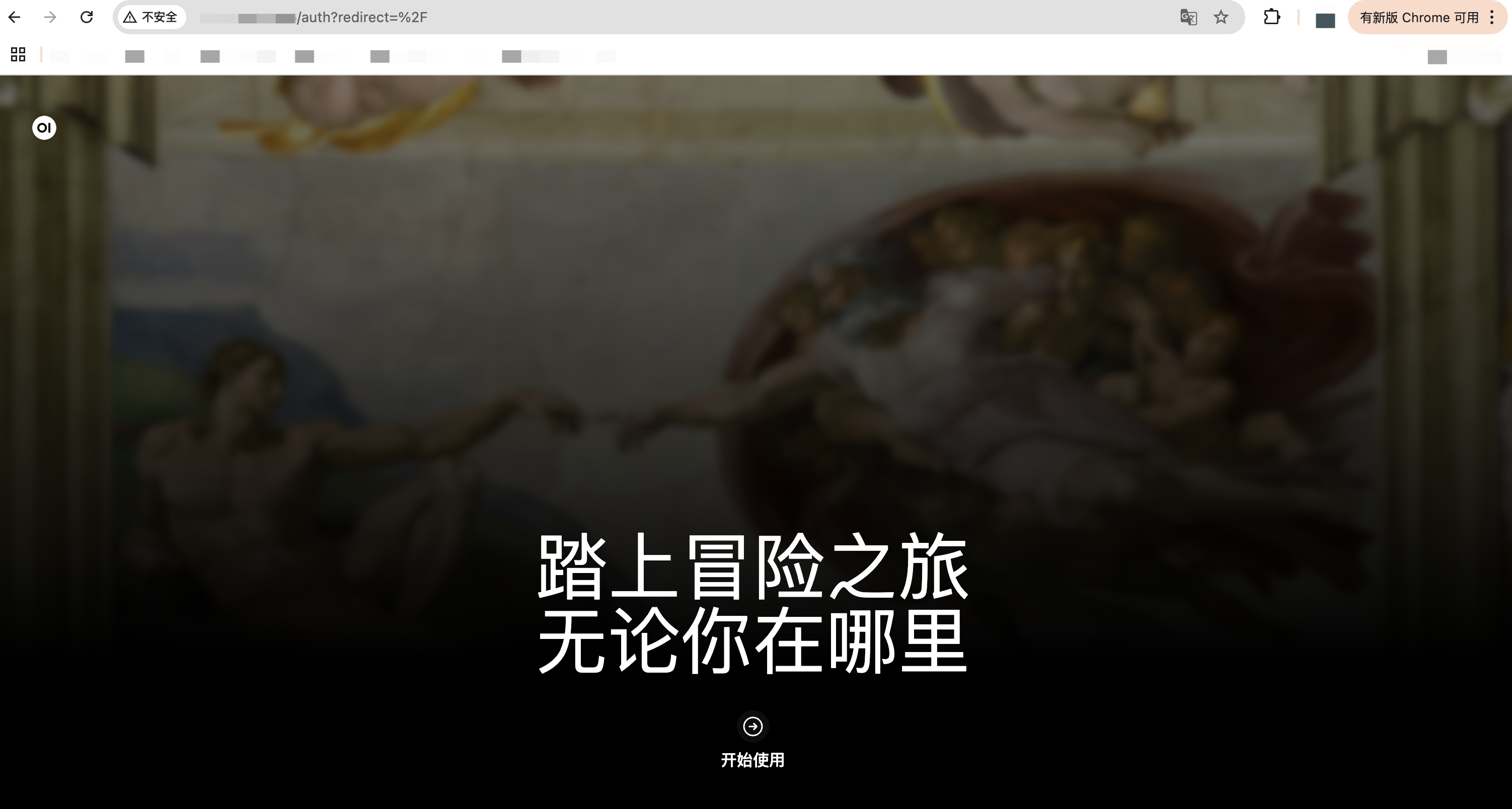
我们在 Open WebUI 的YAML配置中默认配置了前期启动的 QwQ-32B 模型服务和后续我们将部署的 SearXNG 服务,如需定制化调整只需调整对应的参数即可:
containers:
env:
- name: OPENAI_API_KEYS # 多个 API Key 用分号分隔
value: "sk-foo-bar"
- name: OPENAI_API_BASE_URLS # 多个 API Base URL 用分号分隔
value: "http://<YOUR-PUBLIC-IP>/v1"
- name: ENABLE_RAG_WEB_SEARCH
value: "true"
- name: RAG_WEB_SEARCH_ENGINE
value: "searxng"
- name: SEARXNG_QUERY_URL
value: "http://searxng-1/search?q=<query>"
联网搜索功能的部署
Open WebUI 支持丰富的周边功能,其中联网搜索是最为常用的功能之一。可以自行申请、配置 Google、Baidu、Bing 等搜索引擎的 API,我们这里基于开源方案 SearXNG,提供一个易部署的私有化搜索方案,可以提供更具隐私安全的搜索体验。
- 部署联网搜索功能的示例 searxng.tpl.yaml,文件中包含Deployment和公网IP的Service以及一个1GiB的共享存储卷PVC,yaml示例如下:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: searxng-data # 存储卷的名称
spec:
accessModes:
- ReadWriteMany # 存储卷的读写模式
resources:
requests:
storage: 1Gi # 存储卷的容量大小
storageClassName: shared-nvme-cn-huabei1 # 创建存储卷使用的StorageClass的名字
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: searxng-1
namespace: default
labels:
app: searxng-1
spec:
replicas: 1
selector:
matchLabels:
app: searxng-1
template:
metadata:
labels:
app: searxng-1
spec:
volumes:
# 挂载分布式存储盘(如需要)
- name: data
persistentVolumeClaim:
claimName: searxng-data
- name: shm
emptyDir:
medium: Memory
sizeLimit: "2Gi"
- name: public-data
hostPath:
path: /public
containers:
- name: searxng
image: registry-cn-huabei1-internal.ebcloud.com/docker.io/searxng/searxng:latest
command:
- sh
- "-c"
- |
rm -f /etc/searxng/settings.yml /etc/searxng/limiter.toml
if [ ! -f /root/.searxng/settings.yml ]; then
cp /public/shared-resources/searxng-config/settings.yml /root/.searxng/
fi
if [ ! -f /root/.searxng/limiter.toml ]; then
cp /public/shared-resources/searxng-config/limiter.toml /root/.searxng/
fi
cp /root/.searxng/settings.yml /etc/searxng/
cp /root/.searxng/limiter.toml /etc/searxng/
# export SEARXNG_BIND_ADDRESS=0.0.0.0
# export SEARXNG_PORT=8080
export SEARXNG_SECRET=ABABAB
# export SEARXNG_LIMITER=true
# export SEARXNG_PUBLIC_INSTANCE=true
/usr/local/searxng/dockerfiles/docker-entrypoint.sh
env:
- name: HF_ENDPOINT
value: "https://hf-mirror.com"
ports:
- containerPort: 8080
resources:
limits:
cpu: "4"
memory: 8G
requests:
cpu: "2"
memory: 4G
volumeMounts:
- name: shm
mountPath: /dev/shm
- name: data
mountPath: /root/.searxng/
subPath: searxng-data-mount
- name: public-data
mountPath: /public
---
apiVersion: v1
kind: Service
metadata:
name: searxng-1
namespace: default
spec:
ports:
- name: http-searxng-1
port: 80
protocol: TCP
targetPort: 8080
# The label selector should match the deployment labels & it is useful for prefix caching feature
selector:
app: searxng-1
sessionAffinity: None
# 指定 LoadBalancer 类型,用于将服务暴露到外部,自动分配公网 IP
type: LoadBalancer
# 部署 SearXNG 服务,服务一般会在 30s 内启动完成,默认我们配置了国内可稳定访问的部分搜索服务
kubectl apply -f searxng.tpl.yaml
部署完成后,我们就可以在 Open WebUI 的页面上使用“联网搜索”功能了。